一、要求
(一)现有如下命令:echo -e "abb\nabbc\nabc\nb\nbb\ncb\n" | grep '^a*b',写出该命令的结果,并具体说明其中的正则表达式的含义
(1)解答
输出结果如下:
abb
abbc
abc
b
bb含义:匹配以a作为行首开头的、重复1次到多次直到为b字符的字符串,如:ab、aab、aaab
(2)验证
输入指令:echo -e "abb\nabbc\nabc\nb\nbb\ncb\n" | grep '^a*b'

(二)创建文件 File1,利用 grep 命令输出所有以“wuhan2020”开始的字符串;输出包含“wuhan2020”的字符串;输出“wuhan2020”后面跟着 1 到 4 个 a 的字符串;输出含有必选字符“wu”且紧邻该字符右侧为可选字符“o”或者“k”的字符串;输出不含有“a”或“b”或“c”的字符串
采用Vim创建的文件File1的内容如下:
---------start-----------
wuhan2020 GanAHE dgzc.ganahe.top
GanAHE dgzc.ganahe.top wuhan2020
www.ganahe.topwuhan2020dgzc.ganahe.top
wuhan2020GanAHEdgzc.ganahe.top
GanAHEwuhan2020www.ganahe.top
wuokkos wukossa wuhan2020ssda wuhan20202a
wuhanwuokkwuhan2020ohwukou
wuhan2020aaaawuhan2020aaa wuhan2020awuhan2020a
----------end-------------(1)输出以“wuhan2020”开始的字符串
采用命令:grep '^wuhan2020' File1:

(2)输出包含“wuhan2020”的字符串
采用命令: grep 'wuhan2020' File1:

(3)输出“wuhan2020”后面跟着 1 到 4 个 a 的字符串
命令:grep 'wuhan2020a\{1,4\}' File1 输出:

(3)输出含有必选字符“wu”且紧邻该字符右侧为可选字符“o”或者“k”的字符串
命令:grep 'wu[ok]' File1输出:

(4)输出不含有“a”或“b”或“c”的字符串
采用 grep -v '[abc]' File1 指令,由参数 -v 输出匹配a、b、c的反向结果即可实现:

查看原匹配效果:

(三)创建数据文件 File2,利用 awk 命令输出每一数据记录的第 2、第3 个字段;输出第 2、第 3 个字段,其中,对第 2 个字段进行“*2”操作;输出第 2、第 3 个字段,其中,传入变量“scale=10”,第 3个字段与变量“scale”做乘法运算;仅仅输出前 3 行的第 2、第 3 个字段
File2采用Linux编辑命令使用:Vim、Sed、awk的最后一部分内容数据处理后的数据进行操作,文件内容如下:

文本数据:
19 +0.02 +0.63 -00035.78 +99156.71 +00057.44
20 -0.05 +0.58 -00302.50 +13673.39 -00000.04
21 +0.13 +0.71 -00723.44 +26627.91 +00045.23
22 +0.02 +0.73 -00292.99 +39570.76 +00007.99
23 +0.04 +0.77 -00713.03 +52480.06 +00045.03
24 -0.00 +0.76 -00322.42 +65412.49 +00000.10
25 +0.02 +0.78 -00427.90 +80455.87 +00034.78
26 +0.05 +0.84 -00376.44 +95546.21 -00011.21根据该文件内容按要求对其进行处理。
(1)awk 命令输出每一数据记录的第 2、第3 个字段
通过$符即可引用记录内的字段,采用NR记录输出的行号: awk '{print NR,": ",2,3}' File2:

(2)输出第 2、第 3 个字段,其中,对第 2 个字段进行“×2”操作
同(1),只需要在$2处修改即可:awk '{print NR,": ",2*2,3}' File2,此处结果输出展示略。
(3)输出第 2、第 3 个字段,其中,传入变量“scale=10”,第 3个字段与变量“scale”做乘法运算
根据awk基本命令格式与法则,待传入变量应放置在BEGIN内,即:awk 'BEGIN{scale = 10}{print NR,": ",2,3*scale}' File2:

(4)仅仅输出前 3 行的第 2、第 3 个字段
仅输出前3行,即通过NR值的判断实现即可: awk '{if(NR<=3){print NR,": ",2,3}}' File2:

(四)创建数据文件 File3,利用 sed 命令删除 File3 中的第 1 行至第 4行,删除操作时测试-f 选项的用法;删除含有“abcde”的行;将文本中字符“abcde”替换为“xyz”;将文本中第 1 行至第 6 行中的字符“abcde”替换为“xyz”
File3文件内容如下:
---------start-----------
GanAHE dgzc.ganahe.top wuhan2020
abcde acsdef abdec abced a
acwuacabcdehanwuokkwuhan2020ohwukou
wuhan2020aaabcdeaawuhan2020aaabcde abcdewuhan2020awuhan2020a
----------end-------------按照要求操作如上文档数据。
如需要直接修改文档并保存替换后的内容,添加-i参数即可。
(1)sed 删除前4行
通过sed删除,可以直接采用指令 sed 1,4d File3 删除:

通过 -f指令,则首先创建指令文件,内容为:
1,4d随后执行 sed -f f_sed_command.txt File3:

可以发现与普通指令的处理结果相同。
(2)删除"abcde"字符串所在行
采用命令sed '/abcde/d' File3实现删除:

(3)替换"abcde"为“xyz”
通过指令:sed -e "s/abcde/xyz/g" File3实现全局替换:

(4)将文本中第 1 行至第 6 行中的字符“abcde”替换为“xyz”
为了查看限定行的替换效果,稍微更改文件内容:
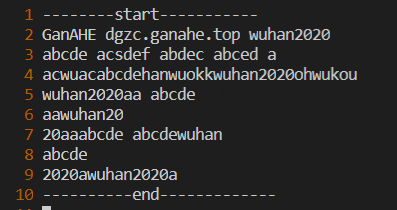
输入指令sed '1,6s/abcde/xyz/g' File3 实现:
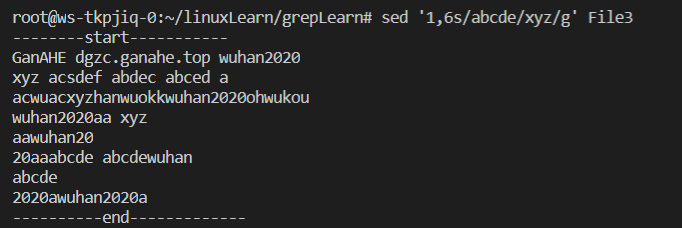
可以发现前六行已经被替换成功,第七行以后的abcde没有被替换。
(五)找到文件 File4 中连续含有三位数字的行,并显示前 10 条记录。
文件File4的数据如下:
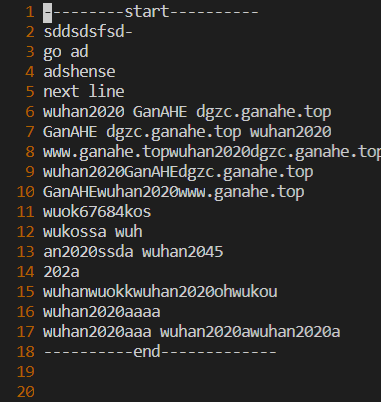
(1)分析
连续含有三位数字即形如:111、123,采用指令:grep '[0-9]\{3\}' File4可以匹配连续含有三位数字的行:

随后采用采用-B参数向前输出指定行即可。
(2)正式指令与输出结果
输入完整命令grep -B 10 '[0-9]\{3\}' File4实现:
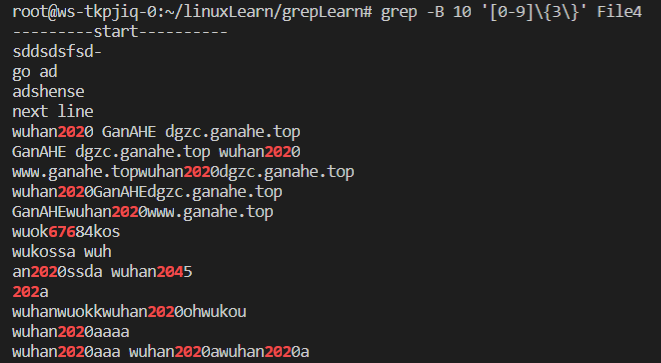
由于后面的行也有满足条件的行,故结果输出较多记录值。
(六)现有如下命令:echo ‐e "aab\nabb\naba\nbab" | grep '\(.\)\1'。写出该命令的结果,并具体说明其中的正则表达式的含义
(1)命令输出与含义
aab
abb含义:匹配含有连续重复两次相同字符的字符串,如aa、bb。
(2)检验
根据指令echo -e "aab\nabb\naba\nbab" | grep '\(.\)\1'输出:

由此我们可以得到其他扩展用法:
匹配以相同字符开头结尾的字符串 : grep '\(.\).*\1'
匹配以b开头和结尾的字符串 : grep '\(a\).*\1'
匹配以b开头和结尾的字符串 : grep '\(b\).*\1'
二、总结
本次内容主要涉及到正则表达式与基本的编辑输出指令,通过如上几个练习,能够有效提升我们对正则表达式的应用以及相应编辑命令的综合处理。
Comments NOTHING