title: python批量实现百度网盘链接有效性检测
tags:
- python
- 网盘
-
链接检测
copyright: true
categories: Python
comments: true
related_posts: true
top: 0
abbrlink: d5641092
date: 2020-05-12 18:18:49
updated: 2020-08-03 08:02:49
(一)初始数据样式
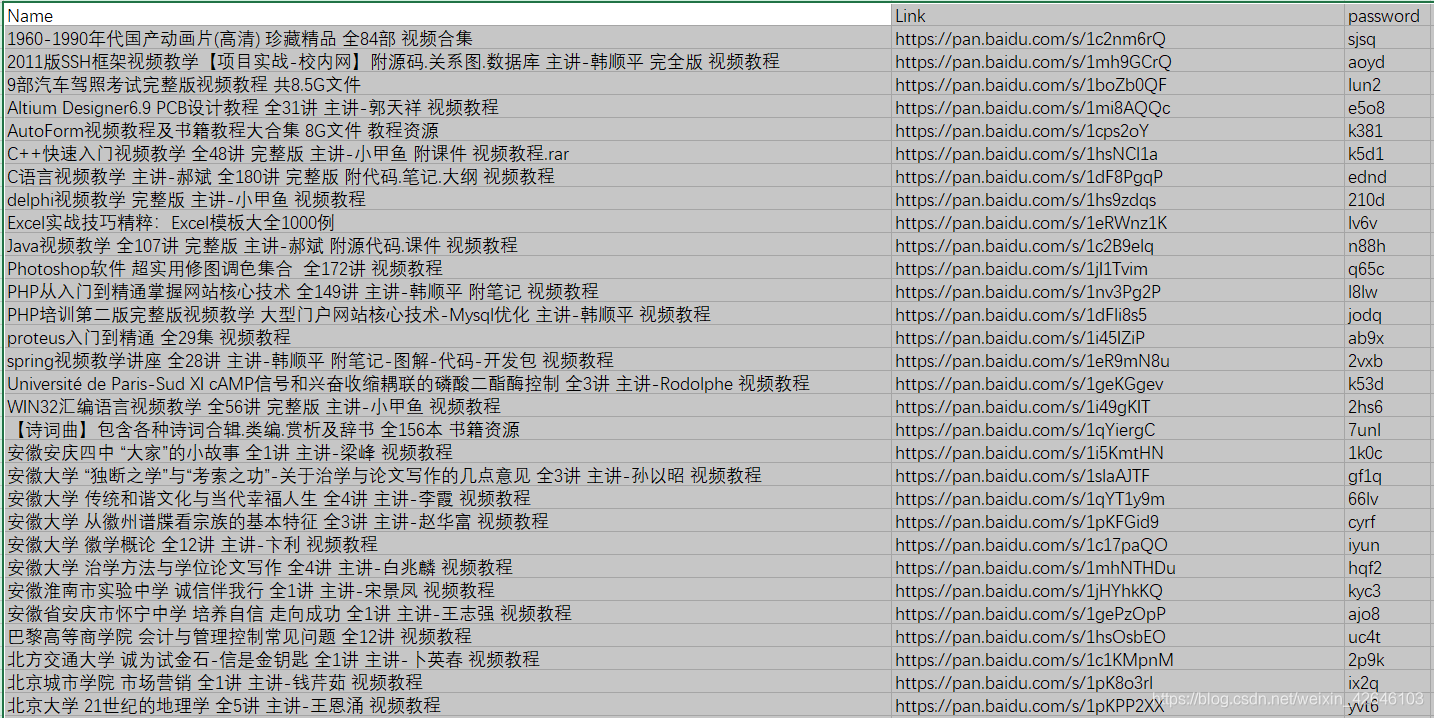
将百度网盘连接存放到 采用逗号间隔的UTF-8类型csv 文件中,数据存放格式为资源名 | 链接 | 密码,如下图所示:
逗号间隔的UTF-8类型csv 文件可以采用Excel转换而得,选择另存为操作即可:
(二)检测
2.1 原理与思路
如链接失效,会出现如下界面:

通过控制台查看返回的代码:

如果链接无效会有标签 class = share-error-left , div_id = share_nofound_des。故可以通过 urllib 库和 bs4.BeautifulSoup 请求并解析HTML,从而判断该标签是否存在。
2.2 设计
通过读取 csv 文件,依次将资源链接传入处理函数,依次判断并保存到新的 resultLink.csv中,作为输出结果。
2.3 代码 Demo
2.3.1 判断与解析代码
# -*- coding: utf-8 -*-
"""
comment: 百度网盘爬虫分析
@author: GanAH 2020/5/12.
@version 1.0.
@contact: https://www.ganahe.top/
"""
import csv
import os
import urllib.request
import time
from bs4 import BeautifulSoup
class BaiduNetdisk(object):
def __init__(self):
pass
def disabledLink(self, link):
"""
链接有效性判断
:param link: baiduNetdisk download Link
:return: 0-False / html-True
"""
try:
print("url", link)
headers = {
'User-Agent': 'Mozilla/4.0(compatible;MSIE 5.5;Windows NT)'
}
req = urllib.request.Request(url=link, headers=headers, method='POST')
response = urllib.request.urlopen(req, None, 8) # 在这里应该加入代理
html = response.read()
return {"code": 1, "status": html}
except Exception as e:
return {"code": 0, "status": e.__str__()}
def anylies(self, link):
resultDict = self.disabledLink(link)
if resultDict["code"] == 0:
print("异常错误!")
print(resultDict.get("status"))
else:
try:
# print(resultDict.get("status").decode('utf-8'))
# ak = str(resultDict.get("status"),encoding = "utf8")
# print(type(resultDict.get("status")))
# for i in range(len(ak)):
# print(ak[i])
soup = BeautifulSoup(resultDict.get("status"), 'html.parser') # 文档对象
# 类名为xxx而且文本内容为hahaha的div
count = 0
# 查找是否有share-error标签,有则无效
print("查找是否有share-error标签,有则无效")
for k in soup.find_all('div', class_='share-error-left'): # ,string='更多'
print(k)
count += 1
if count == 0:
print("链接有效")
return True
else:
print("链接无效")
return False
except Exception as e:
print("异常错误-302:", e.__str__())2.3.2 逻辑处理代码
if __name__ == "__main__":
try:
print("【===百度网盘链接有效性自动判别程序===】n")
print(" * 联系方式n 1.https://www.ganahe.top/ n 2.合作微信公众号:星辰换日n")
# 读取CSV文档
filePath = input(" 请输入文件路径(示例:E:\百度\Link.csv):")
sourceList = []
with open(filePath, "r", encoding="utf8") as F:
for line in F:
# print(line)
sourceList.append(line.split(","))
with open(os.path.dirname(filePath) + "resultLink.csv", "w",newline= "", encoding="utf8") as S:
writer = csv.writer(S)
head = sourceList[0]
head.append("有效性")
print(head)
writer.writerow(head)
for i in range(1, len(sourceList)):
line = sourceList[i]
link = line[1]
print("n ------- 第"+str(i)+"个链接情况:",sourceList[i])
just = BaiduNetdisk().anylies(link)
if just is True:
line.append("有效")
else:
line.append("链接无效")
writer.writerow(line)
print("n-- 结束,所有链接均已分析完成,请打开resultLink.csv查看")
time.sleep(600)
except Exception as e:
print("异常错误-301:", e.__str__())(三) 测试结果
3.1 使用方式
如果 csv 文件与检测代码文件(baiduNetdisk.py,需要python编译环境)或程序(baiduNetdisk.exe,可以在window平台直接执行)在同一文件夹目录下:


可以直接输入文件名[.后缀文件类型]即可。
GIF 展示如下:
如果不在同一文件夹目录下需要输入绝对路径:
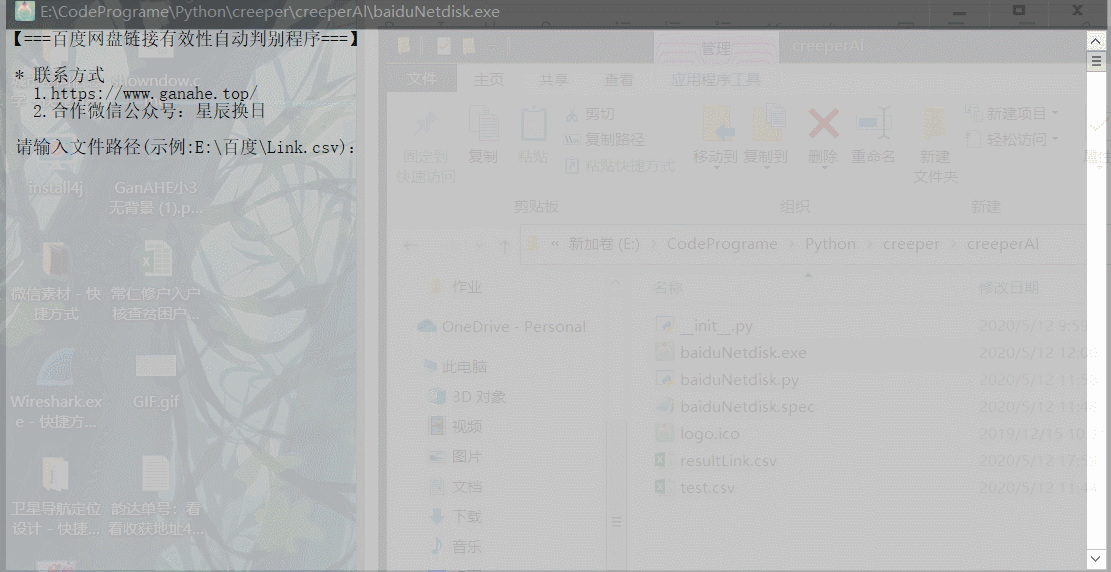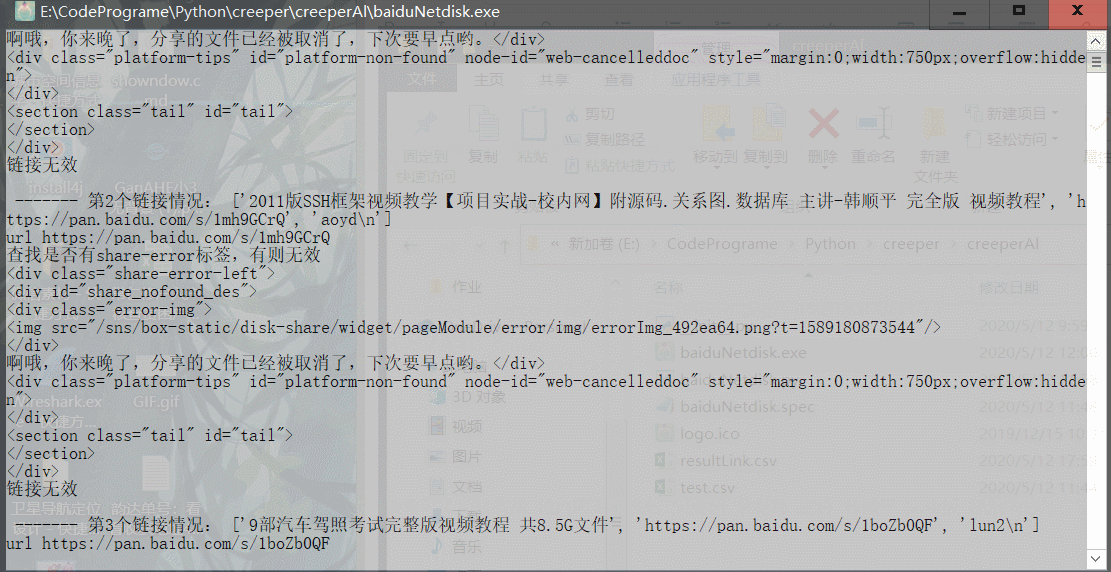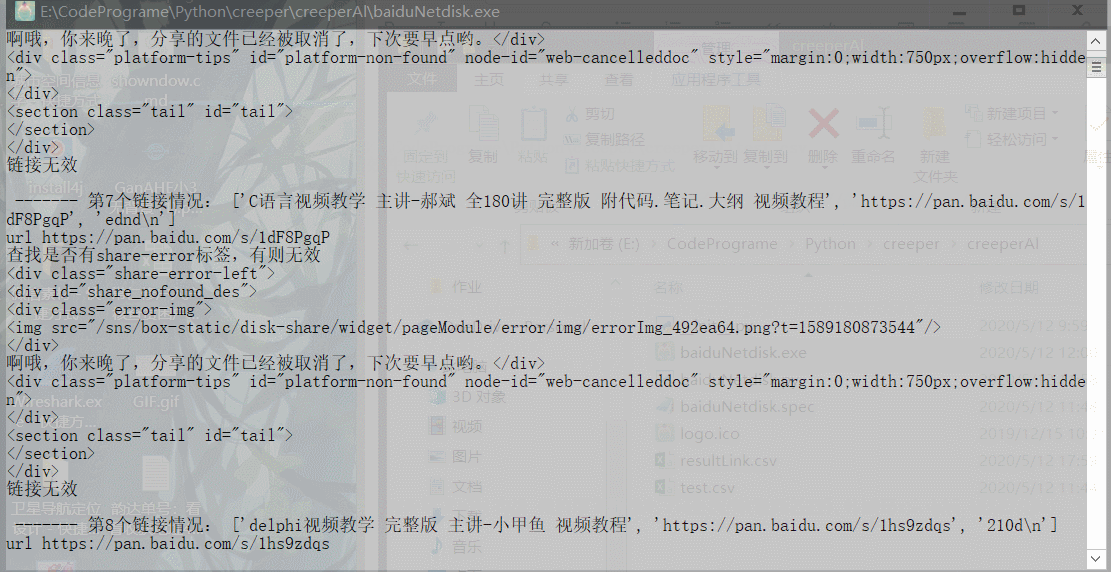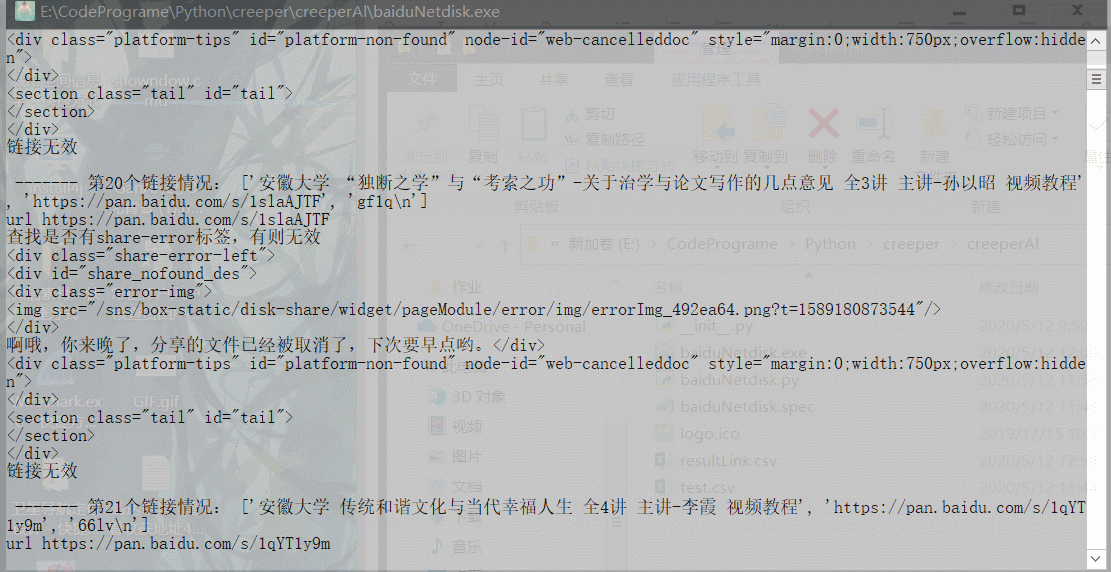
3.2 输出结果


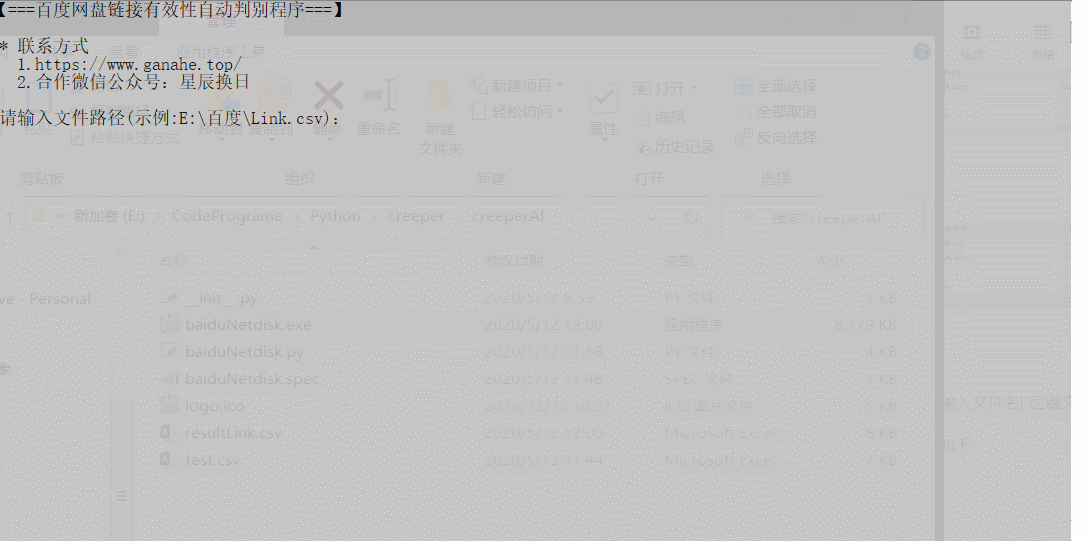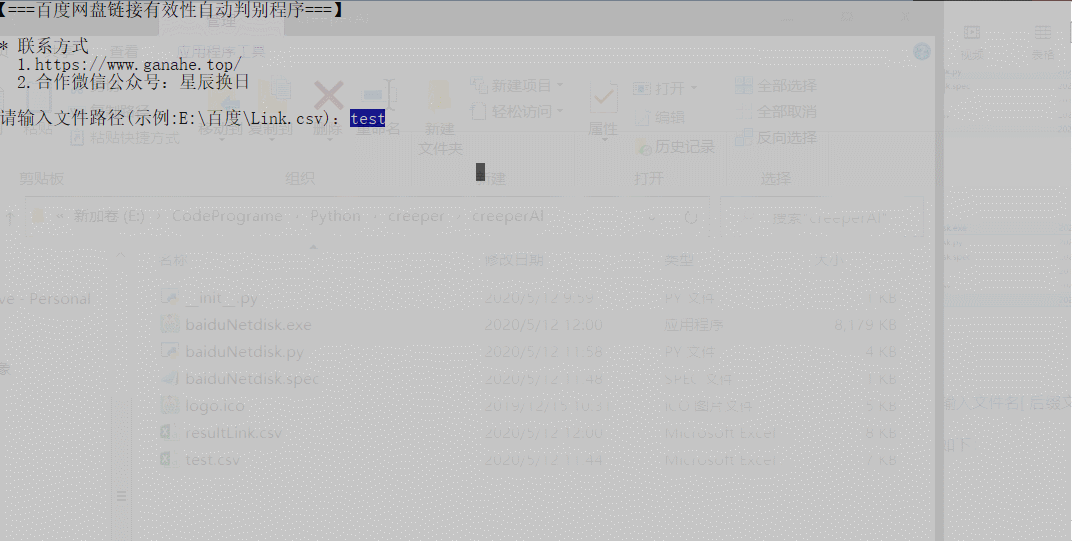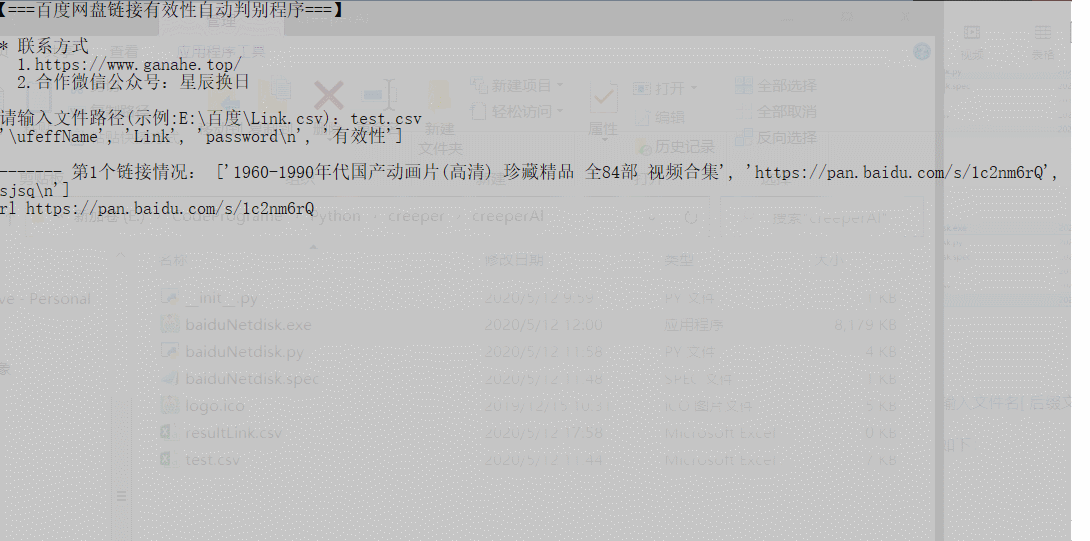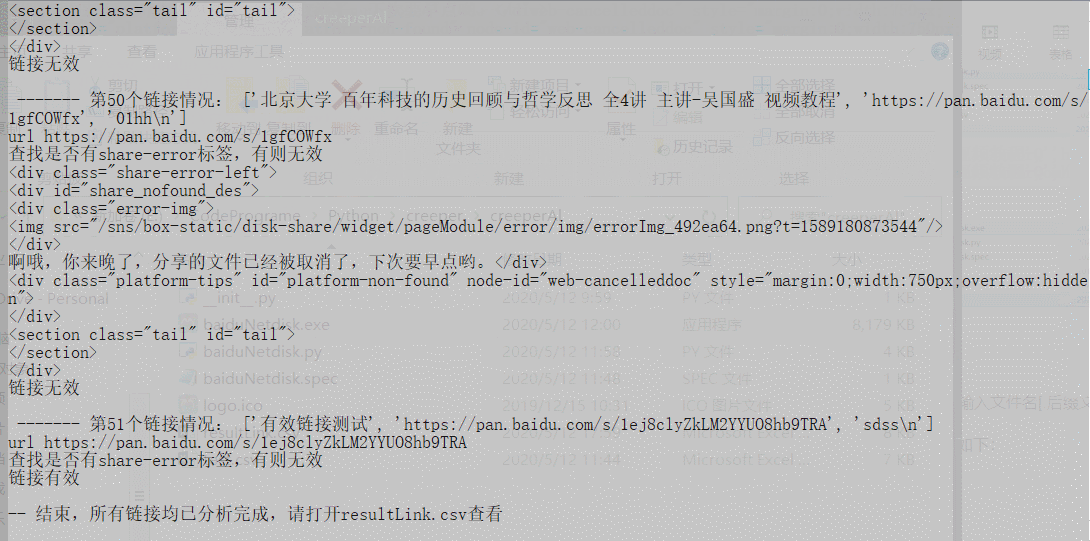
由于大多链接已失效,为了验证是否可以检测出有效链接,特定在末尾加上有效的链接进行测试:

可以发现,有效性得到检验。
(四)获取程序或源代码方式
4.1 Github
4.2 [网盘](https://pan.baidu.com/s/1CXHlUtWmOH2LXxgYi-Q_CA )
点击标题进入下载页面,下载密码的获取方式如下:点击
Comments 1 条评论
[spoiler title=”一个评论折叠功能”] 这是spoiler [/spoiler]