一. 前言与说明
参与一个比赛需要对项目中的验证码进行降噪处理,以便后续的工作。
但是该图像集(5000张)构成十分复杂,有部分图像背景色与字符颜色极为相近甚至达到人眼难以辨别的程度。
例如下图的528.jpg。

二. 初步思路及效果
采用PIL的方法对原始图像读取并处理像素。
转为灰度图像,随后二值化并进行降噪处理。
转换并二值化的算法代码如下:
def two_value(imagePath, listhourd):
"""
图像二值化
:param imagePath:原始未处理图像文件路径
:param listhourd: 二值化阈值,0-255
:return: 返回Image文件类型
"""
# 图像二值化
image = Image.open(imagePath)
# 灰度图
im = image.convert('L')
threshold = listhourd
table = []
for j in range(256):
if j < threshold:
table.append(0)
else:
table.append(1)
im = im.point(table, 'L')
return im
此时效果对于大部分图像尚可。
但同时也发现有部分黑图,以及噪点极多的图像,且大多数图像的噪点仍然比较多,不是很干净。

三. 成图检验分析
(一). 思路
- 将处理后的图像集进行遍历,筛选出质量较差的图像,并按照序号所引进行处理;
- 将影像像素值统计;
- 可视化分析找出差异特征并处理图像;
- 成果导出。
(二). 筛选数据导出
将筛选的图像特征数据导出到 csv 文件中。
代码如下:
# In[011]:
from PIL import Image
import numpy as np
import csv
def fitler_two_value_black(image, filterValue):
"""
筛选二值化后的差图
"""
im = image
data = im.getdata()
w, h = im.size
black_point = 0
# 省去外轮廓,减少非去除噪点干扰
for x in range(10, w - 1):
for y in range(15, h - 1):
pixelData = im.getpixel((x, y))
if (pixelData < filterValue):
black_point += 1
# im.show()
#print("像素占比:", black_point * 100 / (w * h), "%")
return black_point * 100 / (w * h)
def anlyze():
print("start to write ")
header = ["captcha","label","black_point_count"]
with open("./去噪后验证码像素比例分析.csv","w",newline="") as csvFile:
csvWriter = csv.writer(csvFile)
csvWriter.writerow(header)
for i in range(1, 5001):
imagePath = "./testCompResult/" + str(i) + ".jpg"
im = Image.open(imagePath)
point = fitler_two_value_black(im, 1)
listg = [str(i) + ".jpg", "label_None", str(point)]
csvWriter.writerow(listg)
csvFile.close()
print("finish!")
anlyze()(三). 数据可视化分析

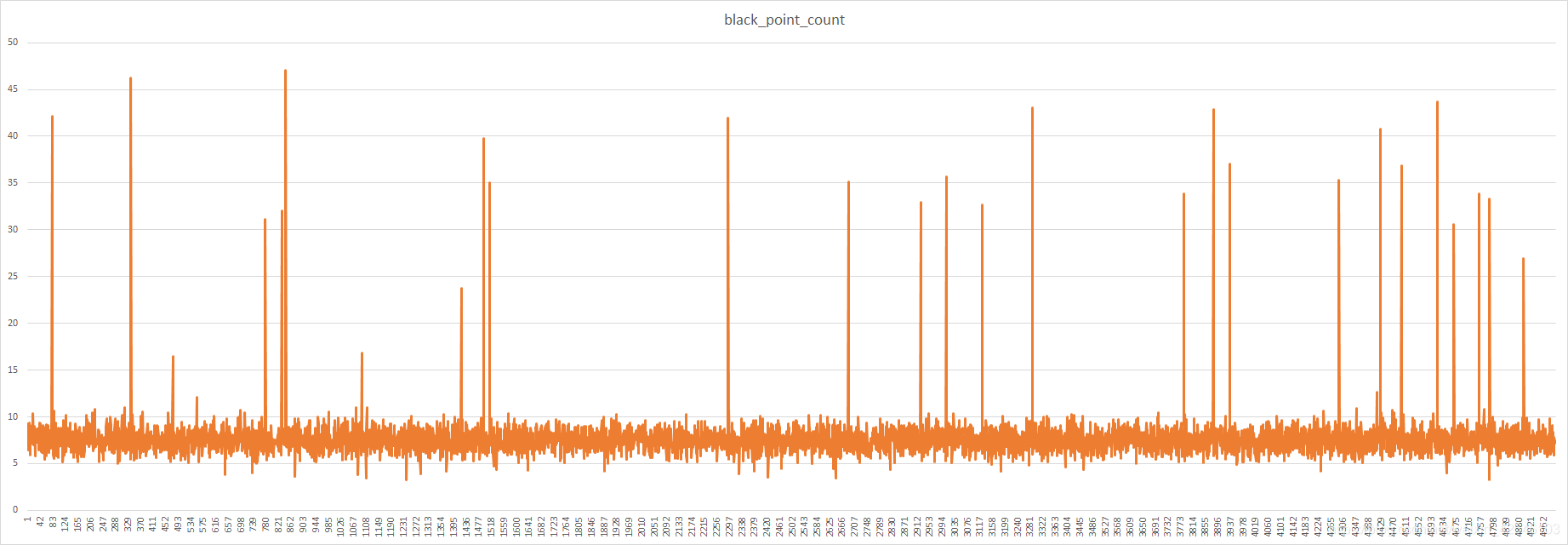
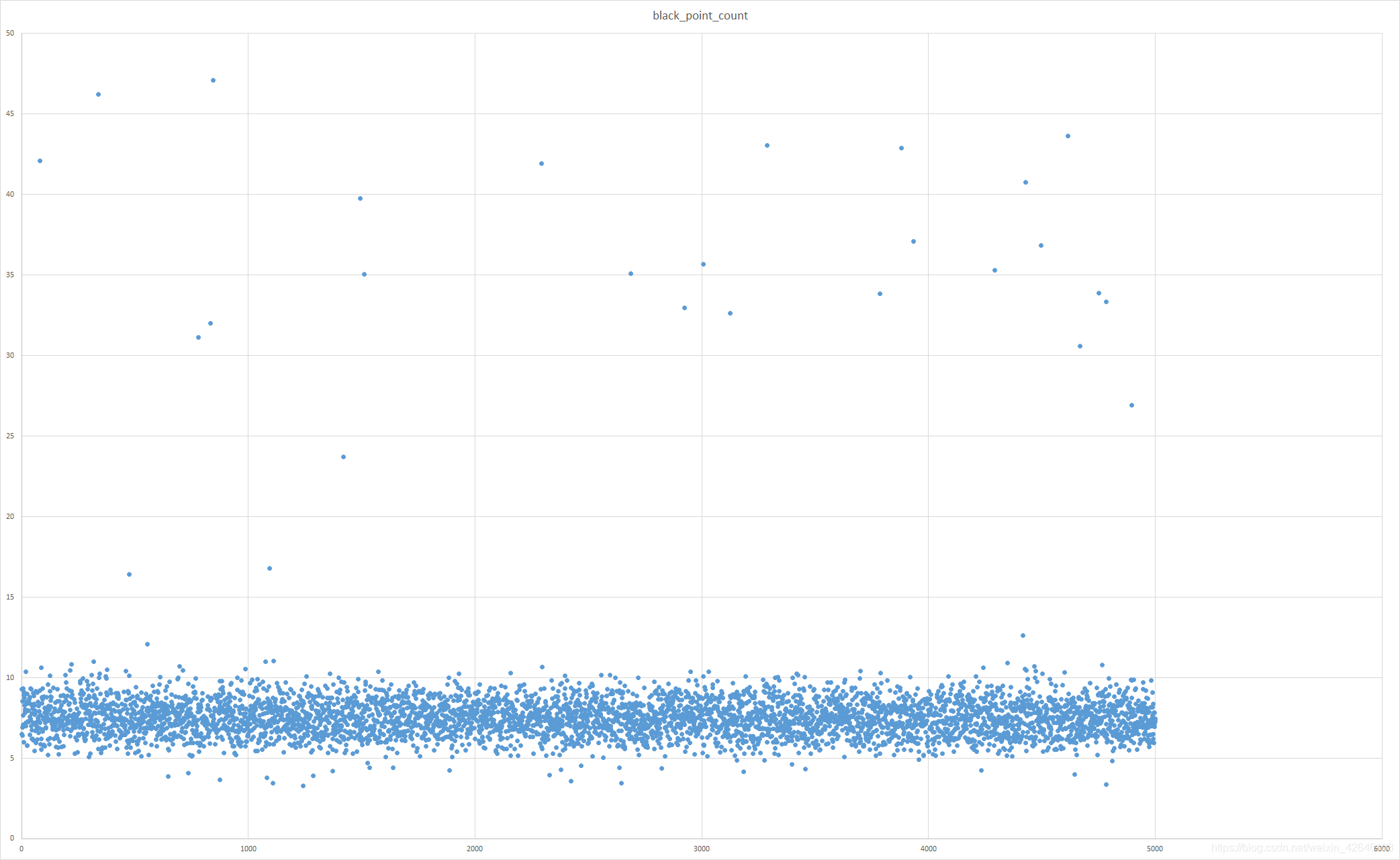
离散分布图中,明显可见检测的黑色点所占百分比有部分图像的 point 值超过了平均值7.6,此即为黑图,小于 5 的为残缺较为严重的图像。
四. 新处理思想探索与效果(较为显著)
(一). 使用 OpenCV 灰度灰度图再进行二值化降噪
此步有利于避免前一步的黑图。
但也引入了新的问题,就是对灰度图的二值化引入了很多噪点:

单张图像放大展示:

对该图再去噪又会破坏文字的完整性,且效果比较差,减小阈值又会造成所需特征缺失,如下图:

(二). 基于 openCV 加入高斯滤波

(三). 对加入滤波后的图像再次进行二值化并去噪

至此,降噪基本达到效果,背景噪点数量极少,字符显示极为清晰透亮,白白净净。
五. 残缺图的产生与验证增强
经过前一步的处理后,虽说去噪效果极好,但我们发现部分图像的字符有所残缺。
经过多次认证测试,摸索出的新办法思想如下:
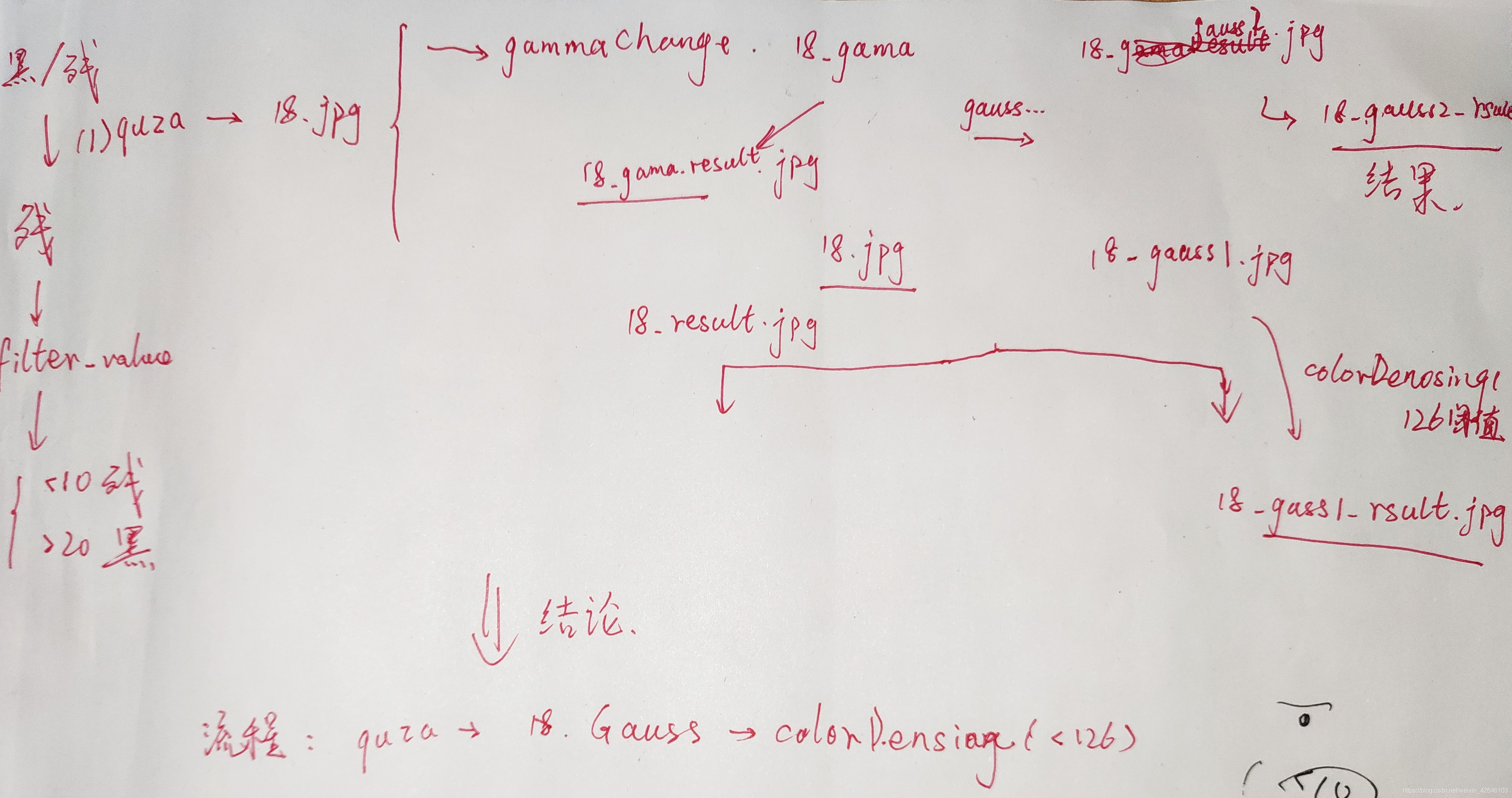
以上流程部分内容代表去噪算法。

以上为图像增强测试主要过程及效果,下面对图像集进行批量处理 :
其中测试用到的增强对比度的算法为伽马算法:
# In[011]:
from PIL import Image
import numpy as np
import cv2
def gammaChange(imagePath, gamma_value):
"""
基于opencv的伽马变换,对图像对比度处理,但是保存后的图像貌似不太对劲,处理黑图
:param imagePath:原始文件路径
:return:numpy类型的 opencv 封装类型,需要使用cv2.imshow(),imwrite()操作
"""
img = cv2.imread(imagePath, cv2.IMREAD_GRAYSCALE)
# 图像归一化
fi = img / 1
# 伽马变换
out = np.power(fi, gamma_value)
return out
六. 降除效果可视化

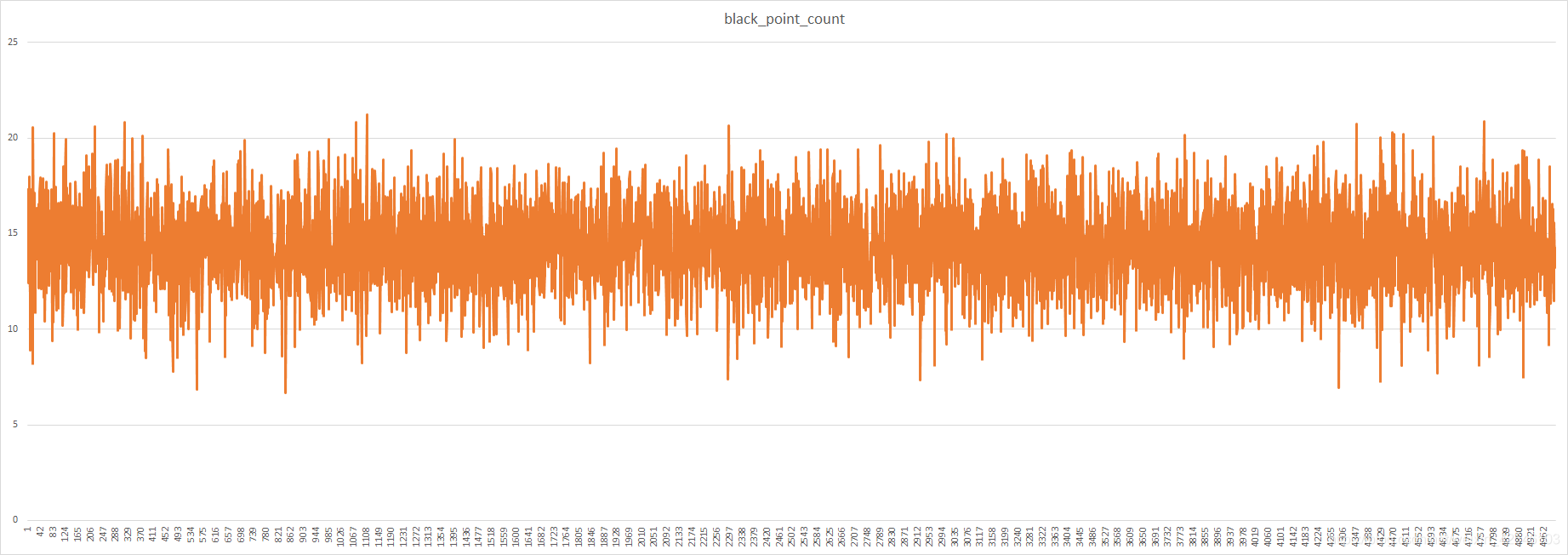
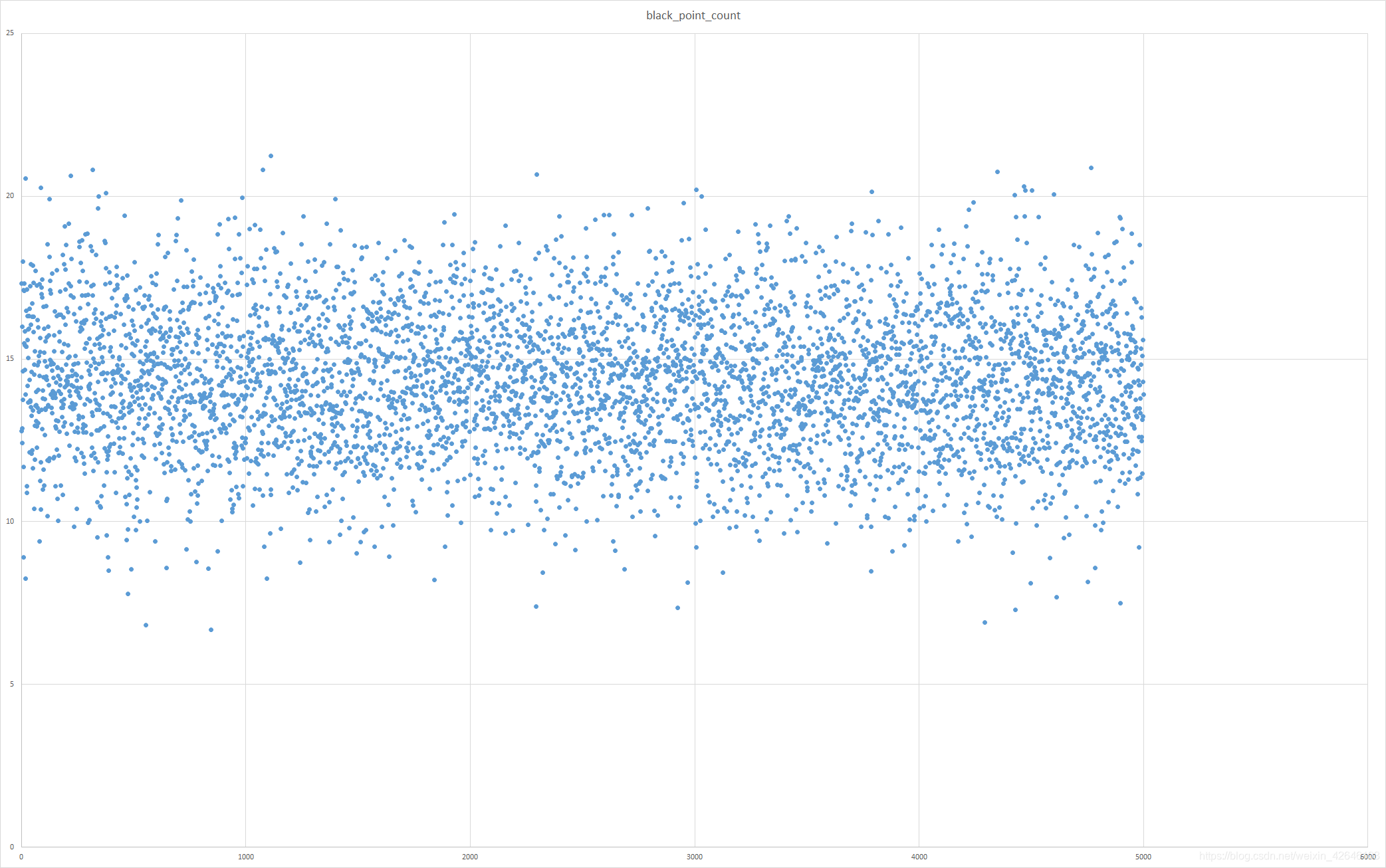
point 无明显偏移情况。

对比图像,去噪效果较为明显,原残缺图像得到增强。
七. 最终效果

八. 不足之处
部分字符颜色与背景色极为接近的图像,在经过处理后,在字符区域会
造成团簇状黑斑,或是字符消失,解决这一问题,需要用到基于
TensorFlow 等框架的深度学习去完成了。
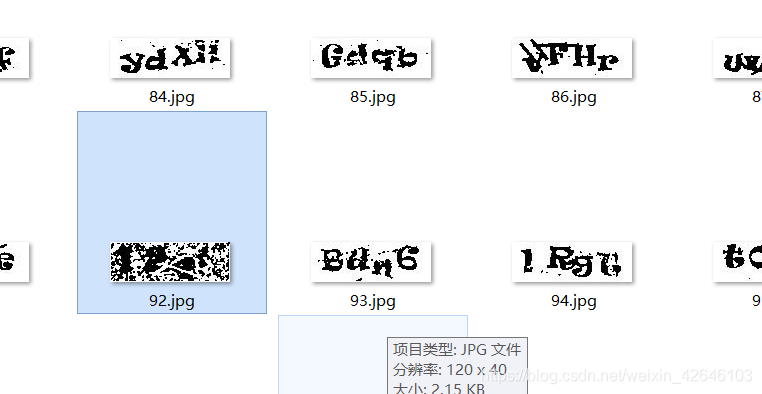
但根据下图的去噪效果分析可见,该类残缺图所占比重较少,具体占比需要依据个人的数据训练集的质量而定:
九. 交流与源代码获取
源代码目前仍在完善中,尚未同步到 GitHub 仓库,有学习需要的伙伴或是想要了解更多内容,请到本人WX
公众号查找往期文章,需要代码可后台回复或是文章内直接获取:

Comments NOTHING